单链表
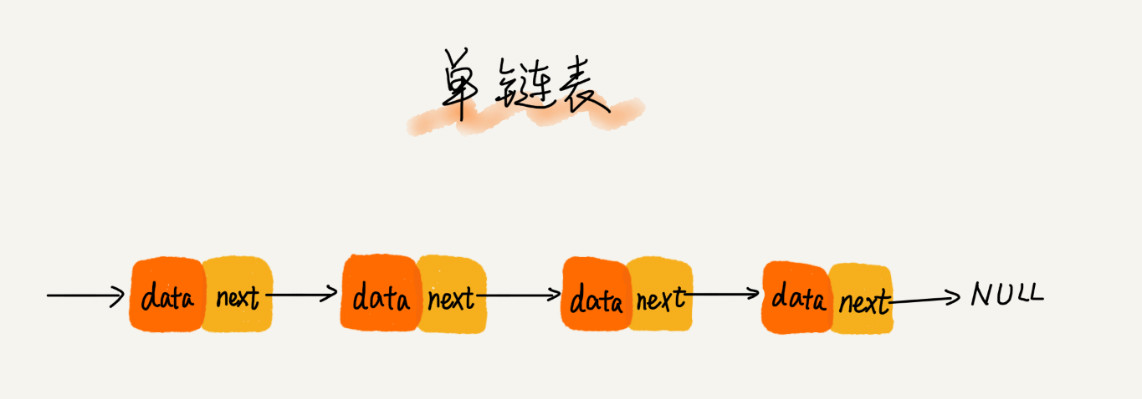
第一个节点叫头结点(记录了链表的基地址,可以用于遍历整个链表),最后一个节点叫尾结点(特殊点在于指针域指向的是空地址null)
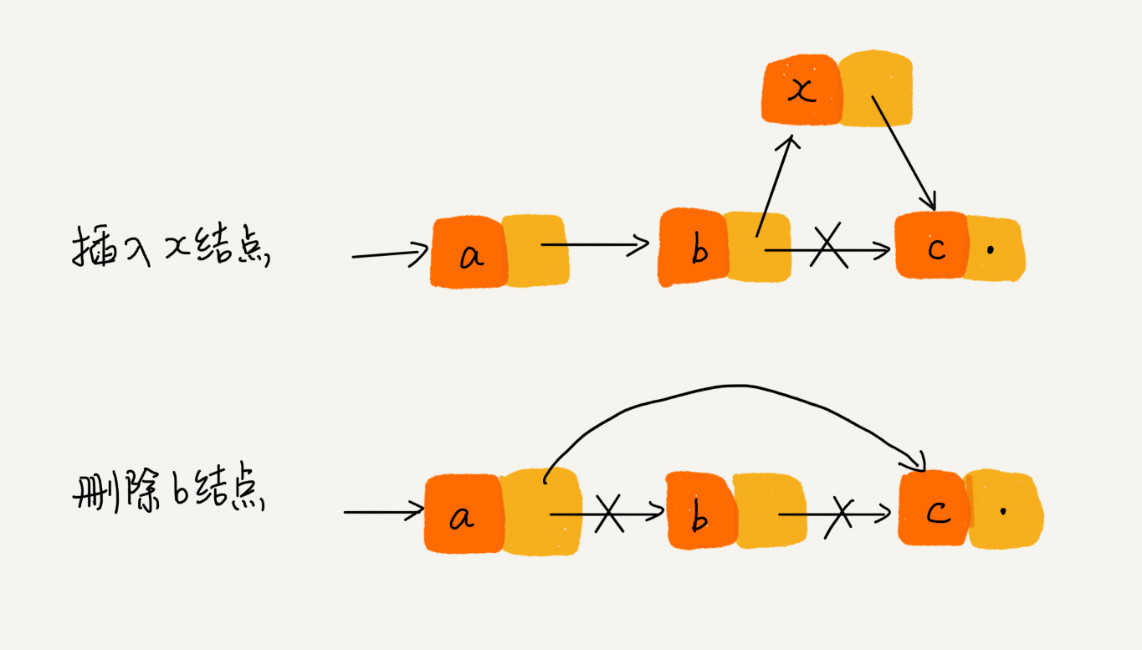
和数组相比:
- 删除、插入操作:链表只需要修改相邻节点的指针域,时间复杂度为O(1)。数组为了保持内存数据的连续性,需要大量的迁移,时间复杂度为O(n)。
- 查询操作:链表数据非连续性存储,需要依据指针域进行遍历,时间复杂度为O(n)。数组通过下标进行直接查询,时间复杂度为O(1)。
双向链表

包含:前驱指针、后继指针、数据域,虽然浪费空间,但是支持双向遍历,操作更加方便
循环链表
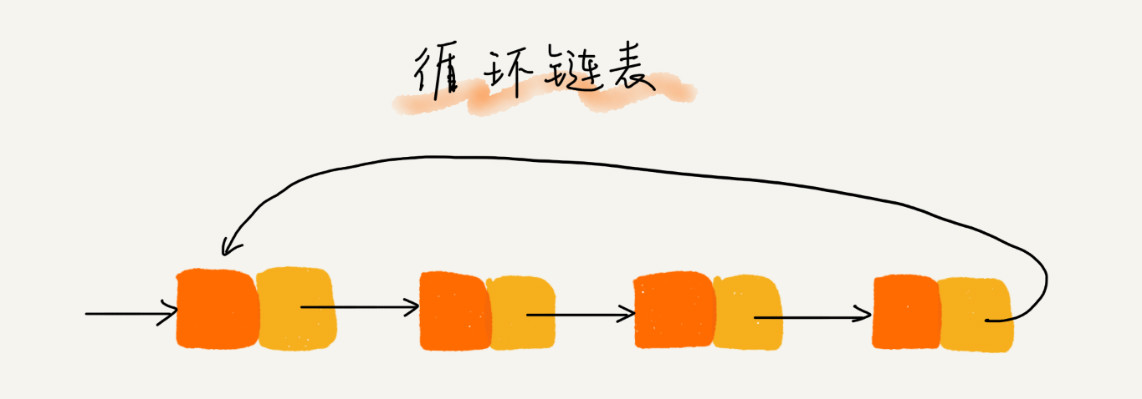
和单链表不同点在于:循环链表的尾结点指针域指向的是头结点
优点:
从链尾到链头比较方便,适用于环形结构的数据。如约瑟夫问题
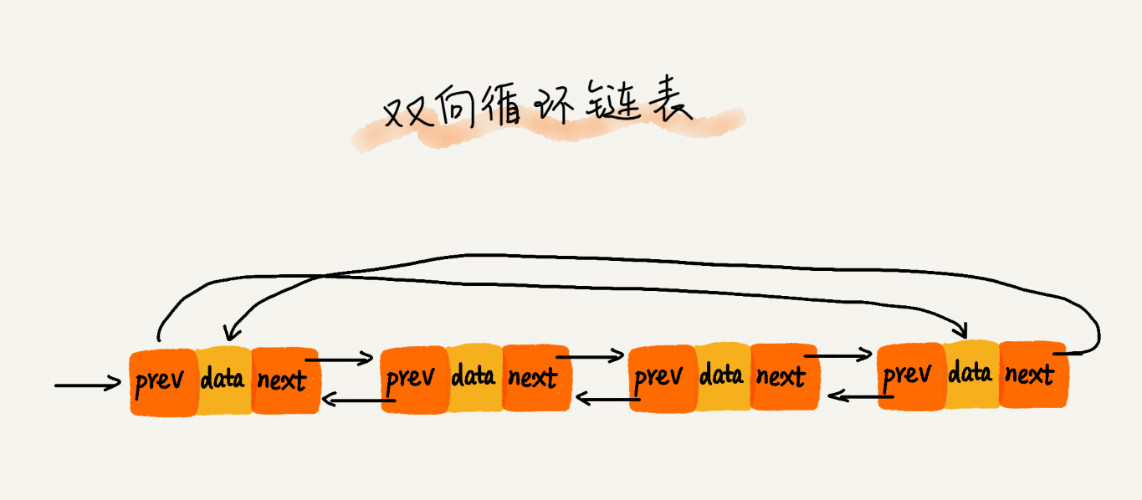
双向循环链表
总结
链表与数组最大的区别在于,链表没有大小的限制,天然支持动态扩容。而数组的缺点是大小固定,一经声明就占用整块连续内容空间,过大可能没有连续空间使用,导致out of memory,过小则会出现不够用的情况,只能申请更多的一块空间,将原数组进行拷贝,比较耗时。
另外链表每一个结点都需要占用额外的空间用于存储指针域,所以内存占用会翻倍。而且,对链表进行频繁的插入、删除操作,还会导致频繁的内存申请和释放,容易造成内存碎片,如果是 Java 语言,就有可能会导致频繁的 GC(Garbage Collection,垃圾回收)。